
External Preprocessing
This page describes how to implement an external preprocessor to integrate with the Nx AI Manager
It is sometimes desired to add custom or proprietary pre-processing to the inference pipeline. It is therefore possible to add a custom application which receives the input frame to the Nx AI Manager and has the opportunity to alter or analyse the input frame.
Examples are provided in how to create these applications. These applications can be created using any programming language, as long as the device can execute this program, send it messages over a Unix socket, and receive a response.
Through the settings, instructions can be provided to the Nx AI Manager on how to start the application. The Nx AI Manager will automatically start the applications on startup, and terminate it when the Nx AI Manager terminates.
The external pre-processor runs as a completely independent application. The Nx AI Manager puts no restrictions on which hardware, API's or tools this application uses. As long as this application can receive and respond to messages over a Unix socket, it will be compatible.
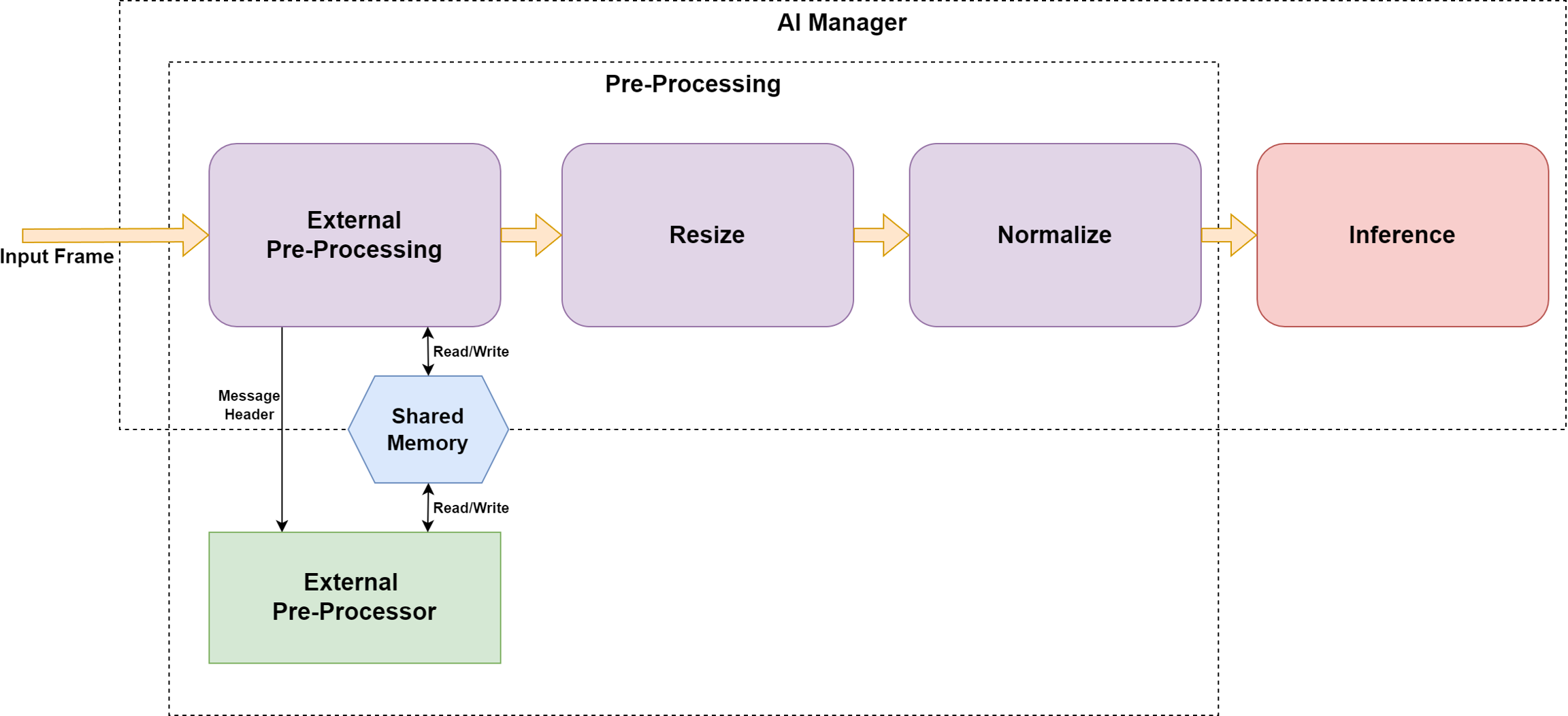
The external pre-processing step happens before any other pre-processing is done on the frame. This means that the external pre-processor receives the original, full resolution image as it was sent to the Nx AI Manager.
The external pre-processor will receive a header message over Unix socket which describes the input frame, as well as provide details on how to connect to the shared memory segment where the input frame is stored. The external pre-processor can then connect to this shared memory, alter the data, or write back a completely new image with new dimensions. The altered data will then be used in the rest of the pipeline.
The Nx AI Manager will wait until the external pre-processor responds with a header message, containing information on the new ( or same ) image dimensions and new ( or same ) shared memory segment containing image data. After this message is received, the Nx AI Manager will copy the data from the shared memory segment and use it for the rest of the inference pipeline.
Custom external processing
If this behavior is not the desired behavior, is possible to create your own preprocessor to create a mask or postprocessor to exclude results from an area that you designate.
For more information on custom preprocessors and postprocessors you can checkout the examples in our GitHub repository

Last updated